The 4 Stages of Training Large Language Models (LLMs): A Complete Guide

In our previous blog post, we discussed some of the most powerful applications of large language models (LLMs) that’ve gained traction across diverse industries. But if you’re wondering how LLMs achieve their desired performance to suit different industries and use cases, you’ve come to the right place.
In this blog, we’ll walk you through how Large Language Models are trained through different stages, showing you how they evolve to generate human-like responses with great accuracy. We’ll also shed light on the key challenges LLMs face at each stage of training and how they’re tackled to refine these models.
Let’s dive in!
With the surge in processing power, vast dataset corpora, and expanded memory capacity, LLMs have undergone a remarkable transformation. Compared to their predecessors from just a few years ago, today’s models have leaped from predicting single words to generating entire sentences, producing full-length reports, and even summarizing them in seconds like it’s no big deal.
But how did we get here? It all comes down to a rigorous, multi-stage training process that fine-tunes an LLM’s ability to understand, generate, and refine text.
The Four Key Stages of Training an LLM
Typically, the process of training a large language model can be carefully divided into 4 stages.
Data Preparation
Model Training through Self-Supervised Learning
Supervised fine-tuning (SFT)
Reinforcement Learning through Human Feedback (RLHF)
Now, let’s dig deeper into each stage of LLM development and explore how it enhances the model’s performance and understanding.
Stage 1: Data Preparation
As you may know, large language models are trained on a massive amount of datasets sourced from a variety of places, such as from websites, books, GitHub repositories, internal databases, and more. This is to help the model learn about different topics, writing styles, linguistic patterns, and variations in observations, essentially, everything it needs to generate contextually relevant and coherent texts.
However, the type of datasets used in training plays a crucial role in shaping an LLM’s accuracy, consistency, and predictive capabilities.
Let’s say you’re training your AI to write compelling product descriptions. Instead of manually teaching it a handful of rules like “use persuasive language” or “understand user intent first”, you feed it with thousands of well-written ads, blog posts, and marketing copies. Over time, the AI analyzes and learns from the patterns, understanding how to create an engaging sentence, which combination of words can drive action, and how variations in tone can impact users’ buying intentions.
But here’s the catch! You can’t just feed your model with all the data available without proper filtering and structuring and expect it to perform as desired.
LLMs need to be trained with high-quality training corpora that align with the model’s respective domain. This process, known as data preprocessing, is a crucial step in data preparation, where raw text data is refined through steps such as:
- Data Profiling
- Data Cleaning
- Data Enrichment
- Data Integration
- Tokenization & Vectorization
- Feature Engineering
- Data Validation
- Data Transformation
Why Data Preprocessing Matters
Without proper data preprocessing, models can suffer from:
Overfitting – When the model memorizes training data instead of generalizing patterns. This is like a student who memorizes answers instead of actually understanding the subject. The model gets too comfortable with its training data and struggles with anything new, leading to wildly inaccurate results when faced with unseen inputs.
Underfitting – The opposite problem, when the model lacks sufficient learning to make meaningful predictions.
Outliers & Noise – When irrelevant, inconsistent, or extreme values distort the model’s learning process, leading to inaccurate and unreliable outputs.
Once the data is processed, it moves through three key phases in training large language models:
- Self-Supervised Learning
- Supervised Learning
- Reinforcement Learning
This brings us to the next stage of model pre-training.
Stage 2: Model Pre-Training Through Self-Supervised Learning
In this stage, the model undergoes pre-training using a self-supervised learning algorithm, using about 70-80% of data prepared in the first stage. This method allows models to train on large amounts of unlabeled data, thereby reducing the over-dependence on costly human-labeled datasets.
Eventually, as the training advances, the model learns to generate its own target labels by predicting missing words or reconstructing corrupted inputs. In other words, the model identifies hidden patterns within the input data by leveraging contextual information from another part of the surrounding text. This approach enhances its ability to understand subtle nuances, dependencies, and relationships in language without direct human supervision.
To learn more about self-supervised learning, check out this session by Yann LeCun, Chief AI Scientist at Meta.
A Peek Inside the LLM Architecture
From the outside, LLMs seem pretty straightforward. You ask a question, and they respond in seconds. But on the inside, it’s a lot more complicated, with multiple hidden layers of connected nodes, similar to neurons in our brain, forming deep neural networks (DNN).
This deep learning architecture is powered by transformers, the real game-changer behind today’s LLMs.
Some of the most well-known transformer-based models include:
GPT (Generative Pre-trained Transformer) from OpenAI
BERT (Bidirectional Encoder Representations from Transformers) from Google AI
T5 (Text-to-Text Transfer Transformer) from Google
LLaMA (Large Language Model Meta AI) from Meta (Facebook)
These transformers power the entire process of understanding, processing, and generating text by analyzing far-reaching dependencies, patterns, and relationships in language.
Typically, a DNN-based Large Language Model (LLM) consists of the following key layers:
Input layer: The model receives raw text input from the user, which is first converted into numerical representations (input embeddings). These embeddings are then positionally encoded, ensuring the model understands the order of words in a sentence before passing them to deeper layers.
Hidden layers: The input data is processed through multiple hidden layers, where the model learns complex linguistic patterns and abstract data representations. Each layer refines the information received from previous layers, transforming raw text into a higher-level representation.
- During training, the model learns pattern-matching techniques by predicting the next word based on previous words in a sequence, a process refined over multiple iterations (aka epochs).
- A loss function measures the difference between predicted outputs and actual results, helping adjust model parameters for improved accuracy.
Output layer: After processing through hidden layers, the model generates an output sequence based on the given input. The output embeddings undergo positional encoding before being decoded into human-readable text.
At this stage, we have our foundation model or the pre-trained LLM, which has been trained on a vast amount of data. It is already capable of performing tasks such as translation, text generation, summarization, and sentiment analysis with considerable accuracy. However, while it can handle a wide range of functions, it may not yet be optimized for the specific tasks it was originally built for.
This is where fine-tuning becomes essential. By refining the model with domain-specific data and targeted training, we enhance its ability to meet specific downstream tasks and improve its overall performance.
With this in mind, we now move on to the next stage: Supervised Fine-Tuning (SFT), where the model is further trained to align with specialized objectives.
Stage 3: Supervised Fine-Tuning (SFT)
Supervised fine-tuning is the next stage in LLM training where the model goes from a well-trained generalist to a domain-specific expert. At this stage, the model gets another round of training, but this time with task-specific datasets from a specific knowledge base that has been labeled and validated by human experts.
This means that the model will be fed with clear instructions and structured examples, enabling it to go beyond basic predictions and actually excel at performing the task it was built for.
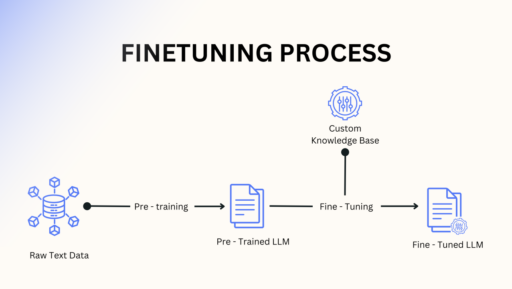
As the training continues, the model becomes more attuned to unseen data, adapts to specific domains, and learns to generalize patterns and nuances from the labeled data. This makes it way better at understanding user intent, generating relevant responses, and handling complex queries.
Supervised fine-tuning isn’t a one-size-fits-all process. There are several fine-tuning techniques to make the model sharper and more efficient. Some of the most commonly used SFT techniques include:
Transfer Learning – Building on what the model already knows using pre-trained knowledge.
Hyperparameter Tuning – Adjusting hyperparameter settings for better performance.
Multi-Task Learning – Training on multiple related tasks at once.
Task-Specific Fine-Tuning – Customizing the model for a particular use case.
Few-Shot Learning – Teaching the model to perform well with minimal examples
Each of these helps fine-tune the model in a way that enables it to deliver smarter, more accurate, and context-aware responses.
Many businesses today are taking advantage of pre-trained LLMs and fine-tuning them for their specific business needs. Because, it’s significantly more efficient in terms of accuracy, computational resources, and cost-effectiveness compared to developing an LLM from the ground up. Fine-tuning allows businesses to enhance the model’s performance in specialized domains such as legal, healthcare, customer service, and finance, ensuring better predictions and more relevant outputs for industry-specific tasks.
Learn more about how LLMs are transforming industries with real-world applications.
Now, your large language model is almost ready. However, it may struggle to make accurate predictions when faced with inputs beyond what it learned during pre-training and supervised fine-tuning. So, to refine its responses and improve adaptability, the final stage that comes into play is RLHF, which we will be discussing next.
Stage 4: Reinforcement Learning from Human Feedback (RLHF)
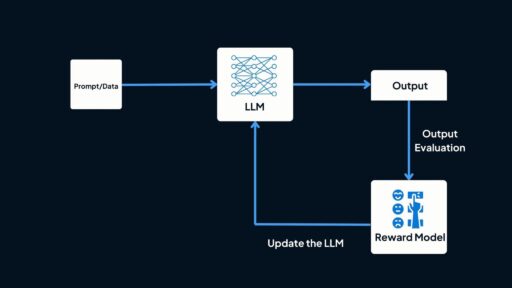
Reinforcement learning from Human Feedback (RLHF) is the final stage of LLM training, where the model’s responses to a particular query or prompt are continuously evaluated and refined based on real-time feedback from human evaluators. This allows the model to learn and emulate the way humans think and respond to certain situations, enabling it to adapt to human reasoning while continuously learning from expert insights.
One of the key techniques used in RLHF is Reward Modeling. In this approach, a separate reward model is trained to assess and rank the quality of the LLM’s responses. The model is rewarded for high-quality, accurate outputs and punished for incorrect, irrelevant, or nonsensical ones.
For example, if you’re fine-tuning a customer support LLM for the healthcare industry, you want it to respond with empathy– a quality that is difficult to quantify through traditional algorithms. With RLHF, human reviewers can rate the model’s responses based on how well they convey empathy. Over time, the reward model learns to optimize for this factor, thereby efficiently guiding the LLM to provide responses that align with human expectations, rather than solely relying on training data.
To further refine LLMs decision-making capabilities, the reward model uses Proximal Policy Optimization (PPO). It’s a reinforcement learning technique that helps the LLM fine-tune its behavior before generating a response. This allows the model to optimize for better rewards, ultimately making its answers more truthful, helpful, and contextually appropriate.
Another important method in RLHF is Comparative Ranking, which is used when multiple human evaluators provide feedback. Instead of assigning absolute scores to responses, this technique compares different outputs and ranks them based on preference. This approach ensures that the model improves based on collective human judgment, rather than the subjective rating of a single reviewer.
Basically, RLHF is a continuous refinement process where the model generates responses, gets critiqued on its quality, learns from feedback, and fine-tunes itself to improve. This cycle keeps repeating until the model aligns better with human values and preferences while ensuring safe and responsible interactions.
However, RLHF comes with its own set of challenges. Since it primarily relies on the man-in-the-loop approach for refining outputs, there is always a risk of introducing human biases, which can unintentionally shape the model’s responses and lead to AI bias. Additionally, the process is resource-intensive, requiring continuous human evaluation and feedback, making it both time-consuming and costly to scale effectively.
Summary
In this blog, we’ve explored the key stages of training an LLM and how it evolves to perform its intended tasks with accuracy and efficiency.
But what’s important to note is that the world of LLMs is constantly evolving, driven by human curiosity and computational breakthroughs. Every dataset we feed, every parameter we adjust, and every fine-tuning method we invent is a step towards pushing the boundaries of what can be done and achieved to meet human needs. Even the techniques and strategies that worked today may be obsolete tomorrow. And that’s the beauty of it.
Learn about our AI app development service.
Frequently Asked Questions
Training an LLM typically follows four major stages: data preparation, self-supervised pre-training, supervised fine-tuning, and reinforcement learning with human feedback (RLHF). The blog explains each step in detail — from cleaning massive datasets to refining responses using human-graded outputs.
Data preparation ensures the model learns from high-quality, diverse, and clean datasets. Proper filtering reduces noise, biases, and inaccuracies, resulting in more reliable and safer model outputs.
Self-supervised learning allows the model to learn language patterns by predicting masked or missing text without manual labels. This forms the foundation of the model’s grammar, reasoning ability, and general knowledge.
Supervised fine-tuning uses human-labeled examples to teach the model how to respond accurately to instructions or domain-specific tasks. It helps the LLM understand context, intent, and proper response formatting.
RLHF trains the model to prefer answers that humans rate as more helpful, safe, and relevant. This reduces harmful responses and improves overall alignment with user expectations.
Training data includes websites, books, academic papers, conversation logs, code repositories, articles, and other large-scale text sources. Diversity in data helps the model generalize across topics.
Challenges include high computational cost, ensuring data quality, managing bias, maintaining safety, and efficiently scaling infrastructure. Each challenge affects model reliability and ethical behavior.
Training an LLM requires extensive computational resources, typically involving multi-GPU or TPU clusters with high memory bandwidth. Large-scale models may need weeks of continuous distributed training.
Pre-training teaches the model broad language understanding using massive open-domain datasets. Fine-tuning adapts the model to follow instructions or perform specialized tasks through smaller curated datasets.
Businesses gain models that are more accurate, safer, and capable of understanding specific workflows. This leads to improved automation, better customer interactions, streamlined operations, and enhanced decision-support tools.











